
Machine learning pipelines are no longer experimental projects. They are mission-critical systems powering personalization engines, fraud detection, forecasting models, and recommendation platforms. However, as these pipelines grow in complexity, the risk of silent data failures increases.
Unlike traditional software systems, machine learning (ML) pipelines depend heavily on data quality, consistency, and timeliness. Even a minor anomaly in upstream data can degrade model performance without triggering obvious system errors. This is where data observability becomes essential.
Data observability enables organizations to monitor, track, and understand the health of their data across the entire ML lifecycle — from ingestion to transformation to model inference.
Understanding Data Observability in ML
Data observability refers to the ability to fully understand the state of data in a system by examining outputs, logs, metrics, and metadata. In machine learning pipelines, it focuses on ensuring that data remains accurate, complete, and reliable at every stage.
Why Traditional Monitoring Is Not Enough
Traditional monitoring tools track system uptime, CPU usage, or application errors. But ML failures are often data-related, not infrastructure-related.
For example:
- A feature column might suddenly contain null values.
- Data distributions may shift due to seasonal behavior.
- Upstream APIs may change schema formats.
None of these issues crash the system. Yet they can drastically reduce model accuracy.
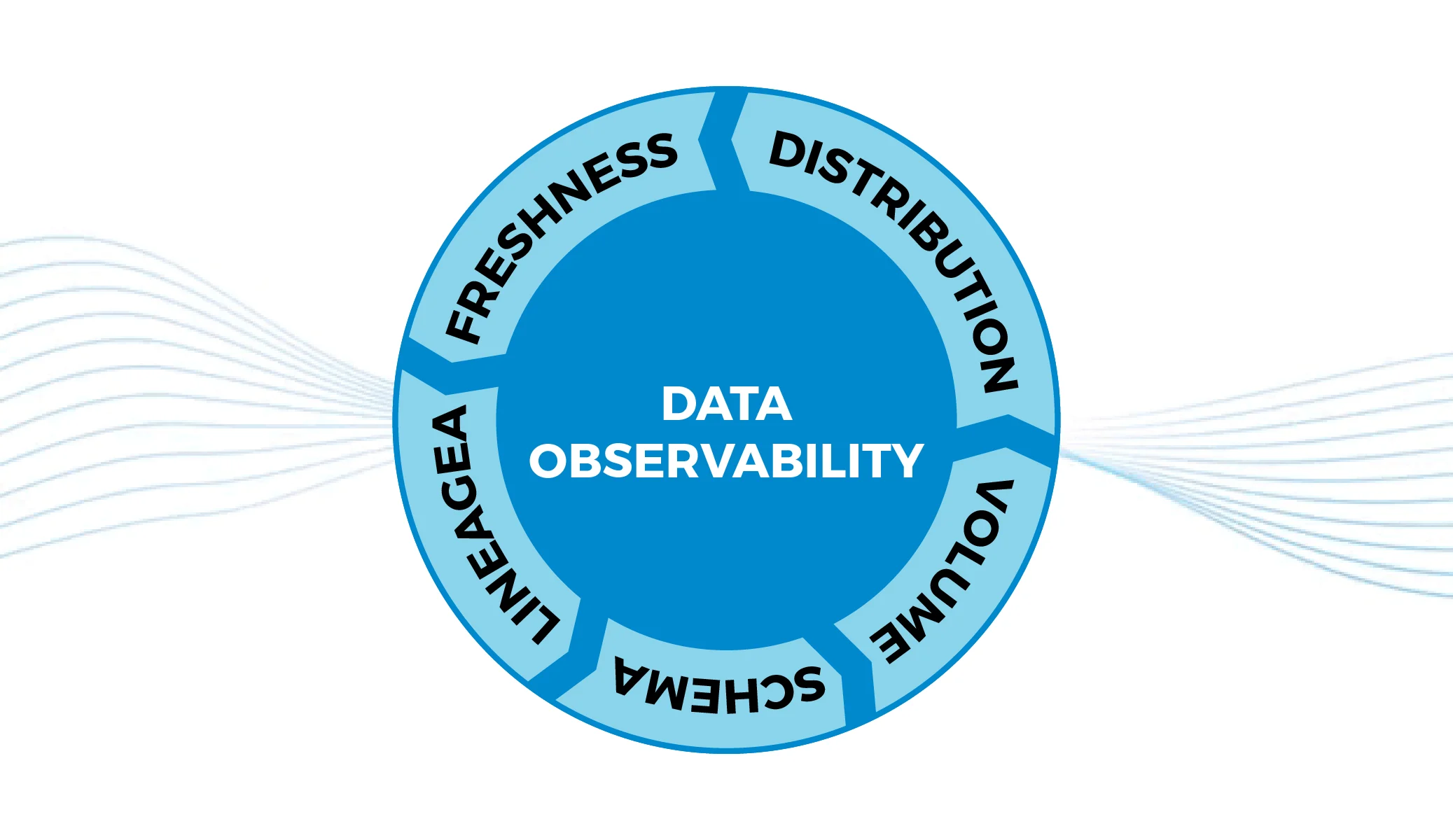
The Five Pillars of Data Observability
Most modern frameworks define data observability across five key dimensions:
- Freshness – Is data arriving on time?
- Volume – Has the number of records changed unexpectedly?
- Schema – Have data structures changed?
- Distribution – Are statistical patterns shifting?
- Lineage – Where is the data coming from and where is it used?
When implemented properly, these pillars provide visibility across the entire ML workflow.
Architecture of an Observable ML Pipeline
Building observability into ML systems requires architectural planning. It cannot be added as an afterthought.
Data Ingestion Layer
At the ingestion level, observability ensures that:
- All expected sources are connected.
- APIs and batch feeds are functioning.
- Data contracts are maintained.
Organizations often rely on Data Integration Engineering Services to streamline ingestion processes across multiple systems. These services help establish structured pipelines that are easier to monitor and maintain, reducing the risk of inconsistent upstream data.
Data Transformation & Feature Engineering
Transformation stages introduce high risk because data is cleaned, aggregated, and reshaped. Errors here can propagate silently into models.
Observability tools monitor:
- Null value spikes
- Unexpected aggregations
- Duplicate records
- Feature drift
Feature stores, when integrated with observability layers, provide centralized tracking of feature health.
Model Training & Validation
Training pipelines should track:
- Dataset versioning
- Feature consistency
- Label integrity
- Bias and fairness metrics
If training data deviates from production data distributions, model performance will degrade in real-world deployment.
Model Deployment & Inference
Once deployed, models must be continuously monitored for:
- Prediction drift
- Input distribution changes
- Latency anomalies
- Confidence score fluctuations
Observability ensures feedback loops are established so models can be retrained when necessary.
Data Drift and Model Degradation
One of the most critical challenges in ML pipelines is data drift.
Types of Drift
- Covariate Drift – Input features change over time.
- Concept Drift – The relationship between features and target changes.
- Prediction Drift – Model output distribution shifts.
Without observability, these changes go unnoticed until business KPIs drop.
Real-World Impact
Consider a recommendation engine trained on pre-holiday shopping behavior. Post-holiday trends may significantly alter buying patterns. If drift detection is not in place, recommendations become irrelevant.
This is why mature Data Engineering Services now incorporate automated anomaly detection, statistical profiling, and metadata management into ML workflows.
The Role of Metadata and Lineage
Metadata is the backbone of observability. It provides context about datasets, transformations, and dependencies.
Why Lineage Matters
Data lineage helps teams answer critical questions:
- Which models are using this dataset?
- What transformations were applied?
- What upstream system caused the anomaly?
When a pipeline breaks, lineage reduces mean time to resolution (MTTR) by identifying the root cause quickly.
Automation in Data Observability
Manual monitoring is not scalable. Modern ML environments require automated observability systems.
Key Automation Capabilities
- Statistical anomaly detection
- Schema change alerts
- Automated data quality scoring
- Real-time dashboards
- Incident notifications
Machine learning itself is increasingly used to monitor ML pipelines, creating self-healing systems.
Business Benefits of Data Observability
Organizations that implement robust observability frameworks experience measurable advantages.
Improved Model Reliability
Continuous monitoring reduces unexpected failures and improves prediction stability.
Faster Debugging
With clear lineage and metadata visibility, teams resolve issues quickly instead of spending days tracing pipeline errors.
Enhanced Compliance
Industries such as finance and healthcare require audit trails. Observability provides documentation of data transformations and model decisions.
Cost Optimization
Silent failures can waste compute resources and cloud budgets. Early anomaly detection prevents expensive retraining cycles and faulty deployments.
Best Practices for Implementing Data Observability
Start with Data Contracts
Define clear expectations between data producers and consumers. Schema enforcement reduces unexpected changes.
Monitor at Every Layer
Observability should span ingestion, transformation, storage, and inference stages.
Integrate with DevOps
Combine data observability with CI/CD workflows. Automated testing should include data validation checks.
Establish Cross-Team Collaboration
Data engineers, ML engineers, and business analysts must share visibility into pipeline health. Silos reduce effectiveness.
The Future of Observable ML Systems
As organizations scale AI adoption, the complexity of pipelines will continue to grow. Multi-cloud environments, real-time streaming, and federated learning add new layers of risk.
Future-ready enterprises will treat data observability as a core infrastructure component, not an optional add-on. Advanced platforms will combine observability, governance, and security into unified ecosystems.
The next evolution will involve predictive observability — systems that forecast potential data failures before they occur.
Conclusion
Machine learning pipelines are only as strong as the data flowing through them. Infrastructure stability alone does not guarantee model performance.
Data observability provides the visibility required to detect anomalies, monitor drift, and ensure data reliability across the ML lifecycle. By integrating structured ingestion frameworks, automated validation, and continuous monitoring, organizations can safeguard model accuracy and business outcomes.
In a data-driven economy, observability is no longer optional. It is the foundation for trustworthy, scalable, and high-performing machine learning systems.